OCR 개요
OCR 이란? Text detection + Text recognition
이미지 속의 문자를 읽는 OCR은 크게 문자의 영역을 검출하는 Text Detection + 검출된 영역의 문자를 인식하는 Text Recognition으로 구분된다.
Text Detection
- Object Detection 문제를 Text 찾아내기로 확장한 느낌
- 추가로 Segmentation 기법도 사용되며 문자가 가지는 특성까지 고려한 형태로 발전
Text Recognition
- 검출된 영역의 문자가 무엇인지 인식해 내는 과정
Text Detection
이미지 속에서 문자를 찾아내는 것은 물체를 찾아내는 것과 조금 다른 특징을 가지고 있다.
문자는 몇개가 모여서 단어/문장을 이루므로 이미지 내에서 문자를 검출할 때에는 최소 단위를 정해야한다.
예를 들어 문장 또는 단어 단위로 찾을 경우, 긴 단어나 문장과 함게 짧은길이도 찾아낼 수 있도록 해야한다.

위 그림에서 (e)의 경우 총 파이프라인의 길이가 간결하여 빠르고, 정확한 Text Detection 성능을 보인다고 논문에서는 말하고 있다.
또한 단어단위의 탐지와 글자단위의 탐지가 모두 활용된다.
- 단어단위의 탐지는 object detection의 regression 기반의 detection 방법이다. Anchor(앵커)를 정의하고 단어의 유무와 bounding box의 크기를 추정하여 단어를 찾아낸다.
- 글자단위의 탐지는 글자 영역을 Segmentation하는 방식으로 접근
1. Regression

TextBoxes는 이미지 내에서 문자를 찾아내려는 다양한 기법들이 활용
- 딥러닝 기반의 Detection을 이용하여 단어 단위로 인식
- 네트워크 기본 구조는 SSD : Single Shot multibox Detector를 활용
설명
일반적으로 단어들은 가로로 길기에 Aspect ratio(종횡비)가 크다. 이에 따라 변형을 주는데, 기존 SSD에서는 Regression을 위한 Convolution layer에서 3X3 kernel을 갖는다.
하지만 위의 논문에서는 긴 단어의 feature를 활용하기 위해 1X5로 convolution filter를 정의하여 사용
Anchor box의 aspect ratio를 1,2,3,5,7로 만들고, vertical offset을 적용하여 세로방향으로의 조밀한 단어 배열에 대응하도록 했다.
▶종횡비(Aspect ratio)란?
- 가로와 세로 길이의 비를 의미.
- 가로 : 세로 의 형태로 표현
- 논문에서는 가로와 세로비를 계산하여 하나의 숫자로 표현
▶Offset 이란?
- 특정한 값에서 차이가 나는 값 혹은 차이.
- offset과 오차는 다르다. ==> offset은 차이가 목적에 의해 만들어진 것과 상황에 따라 자연스럽게 발생한 것 모두를 포함하기 때문
vertical offset 활용 설명
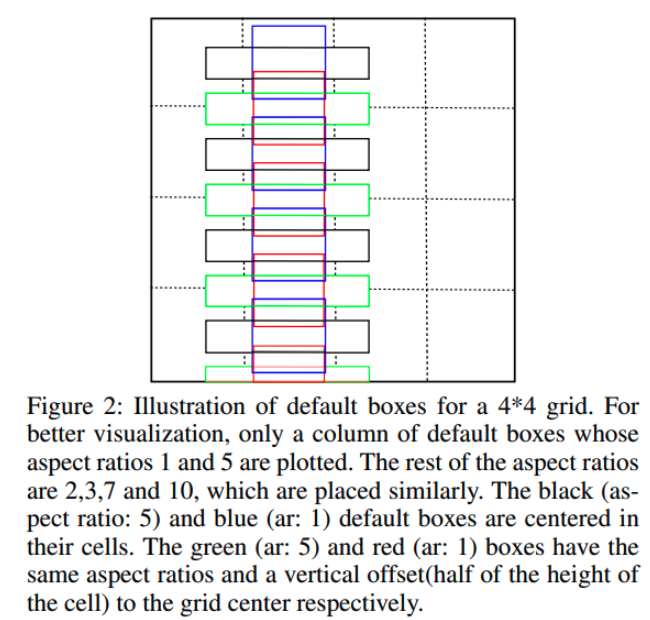
- Grid cell 중앙 기점으로 생성할 경우를 예로 든것이 파란색(aspect ratio:1), 검은색(aspect ratio:1)
- 이를 vertical(수직방향)하게 옮겨서 조밀하게 만든것이 빨간색, 초록색 박스
- 수직방향으로 anchor box의 중앙을 하나 더 채움으로써 세로로 조밀하게 anchor box를 배치가능
2. Segmentation

- Semantic Segmentation 방법을 문자영역 찾기위해 적용하면 배경과 글자 영역으로 분리 가능하다.
- 문자들은 조밀하게 붙어있으므로 글자 영역으로 찾아낸 후에 이를 분리하거나 연결하는 작업을 더 해서 최소단위로 만들어야한다.
- PixelLink 는 Text 영역을 찾아내는 segmentation과 함께, 글자가 어느 방향으로 연결되는지를 같이 학습하여 Text 영역 간의 분리 및 연결을 할 수 있는 정보를 추가적으로 활용

- PixelLink 의 전체적인 구조는 U-Net 과 유사, ouput으로 총 9가지의 정보를 얻는다
- 녹색부분이 input, output을 의미하는데, output 중 하나는 class segmentation map으로, 해당영역이 Text인지 Non-Text인지 예측값을 의미하는 2개의 커널을 가진다.
- 나머지 8가지 정보는 글자의 pixel 중심으로 인접한 8개의 pixel에 대한 연결 여부를 의미하는 16개의 커널로 이루어진 Link prediction map
- 중간의 Conv 1X1, 2(16) 형태의 레이어는 인접 pixel간 연결 구조가 지속적으로 유지 되도록 해서 인접한 pixel이 중심 pixel과 단어 단위로 연결된 pixel인지, 분리된 pixel인지 알 수 있으므로 문자 영역이 단어 단위로 분리된 instance segmentation이 가능해진다.
3. 최근 기술
3.1 Craft
- 문자 단위로 문자의 위치를 알아낸 뒤, 이를 연결하는 방식을 Segmentation기반으로 구현
- 문자영역을 boundary로 명확히 구분하지 않고, 가우시안 분포로 원형의 score map을 만들어서 배치시키는 방법으로 문자영역 학습
- 문자 단위 라벨을 가진 데이터셋이 많지 않기 때문에, 단어 단위의 정보만 있는 데이터셋에 대해 단어의 영역에 inference 한 후, 얻어진 문자 단위의 위치를 다시 학습에 활용하는 weakly supervised learning 활용

3.2 PMTD(Pyramid Mask Text Detector)
- Mask-RCNN의 구조를 활용하여 먼저 Text 영역을 region proposal network로 찾아낸다.
- Box head에서 더 정확하게 regression 및 classification을 한 다음에 Mask head에서 instance의 segmentation을 하는 과정
- PMTD는 Mask의 정보가 부정확한 경우를 반영하기 위하여 Soft-segmentation을 활용한다.
- Mask-RCNN의 경우 단어영역이 그림에서 처럼 Box head에 의해 빨간색으로 잡히면 baseline 처럼 boundary를 모두 text영역으로 잡지만, PMTD는 단어의 사각형 특성을 반영하여 피라미드 형태의 score map을 활용.
Text Recognition
1. Unsegmented Data
Unsegmented Data : 분리에 드는 비용이 많이 들거나 여려워서 Segmentation이 되어있지 않은 데이터
unsegmented data를 활용하기 위해서는??
2. CNN + RNN = CRNN

- Unsegmented data들의 주요한 특징 중 하나는 segmentation 되어 있지 않은 하위 데이터들끼리 sequence를 이루고 있다는 점
- 문자 이미지에서 정보를 추출하기 위해서는 feature Extractor가 필요한데, feature extractor로 사용되는 CNN 기반의 VGG 혹은 ResNet과 같은 네트워크로부터 문자의 정보를 가진 Feature를 얻어낼 수 있다.
- 추출 된 feature를 map-to-sequence를 통해 sequence 형태로 변환한 후 다양한 길이의 input을 처리 할 수 있는 RNN으로 넣는다.
- RNN이 문자를 인식하기 위해서는 문자 영역처럼 넓은 정보가 필요하기때문에 LSTM으로 구성
- 앞의 정보와 뒤의 정보 둘 다 필요하기 때문에 이를 Bidirectional로 구성하여 Bidirectional LSTM을 사용
- 매 step마다 나온 결과는 Transcription Layer에서 문자로 변환된다.
3. CTC(Connectionist Temporal Classification)
- CRNN에서는 step마다 fully connected layer의 logit을 softmax 함수에 넣어주어 어떤 문자일 확률이 높은지 알 수 있지만, output은 24개의 글자로 이루어진 sequence이므로 "HELLO"라는 글자를 넣으면 "HH...HHEEELL...LLOOOO...O" 처럼 24글자가 되어버린다.

- 이를 해결하기 위하여 CRNN에서는 CTC를 활용(input과 output이 서로 다른 길이의 sequence를 가질 때 이를 Align없이 활용하는 방법)
- "HH...HHEEELL...LLOOOO...O"를 "HELLO"로 만들기 위해서는 중복단어들을 하나로 바꾼다. 그럼 "HELO"가 되는데 "L"이 두번 들어가야하는 경우에는?
- Label Encode에서 이렇게 같은 문자를 구분하기 위한 Blank를 중복된 라벨 사이를 구분하기 위해 넣어준다.

- 그림은 Blank token을 " - "로 대신하여 output을 만드는 decoder를 의미한다. Decode 후에 중복을 제거하고, 인식할 문자가 아닌 값을 지워주면 "HELLO"라는 결과를 얻을 수 있다.
4. TPS(Thin Plate Spline)
- 글자를 읽을 때 OCR이 어려워지는 변수 중 하나가 불규칙한 방향 및 휘어진 진행 방향때문
- TPS transformation을 적용하여 입력 이미지를 단어 영역에 맞게 변형시켜서 인식이 되도록 한다.
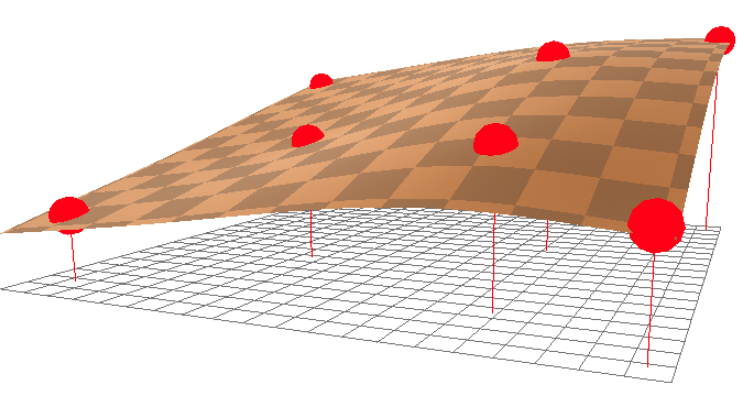
- Control point를 정의하고 해당 점들이 특정 위치로 옮겨졌을 때, 축 방향의 변화를 interpolation하여 모든 위치의 변화를 추정해낸다.
- 전체 이미지 pixel 변화를 control point로 만들어낼 수 있다.

- 위 그림의 논문에서는 control point 20개를 미리 정의하고 Spatial Transformer Network를 통해서 Control point가 얼마나 움직여야 하는지 예측하는 네트워크를 Recognition model 앞단에 붙여 input image를 정방향으로 맞춰준다.
Spatial Transformation Network란? : https://3months.tistory.com/197
Text recognition + Attention
1. Attention sequence prediction

- CTC를 활용한 CRNN의 경우, column에 따라서 prediction된 label의 중복을 제거해 줌으로 원하는 형태의 label로 만들어주었다.
- Attention 기반의 sequence prediction은 문장의 길이를 고정하고, 입력 feature에 대한 Attention을 기반으로 해당 글자의 label을 prediction한다.
- RNN으로 첫번째 글자에서 입력 feature에 대한 attention을 기반으로 label을 추정하고 그 label을 다시 입력으로 사용하여 다음 글자를 추정
- 20글자를 뽑겠다고 정하면 20글자 미만의 단어들에는 빈자리가 나오는데 미리 정해둔 Token을 이용한다.
- start토큰과 end토큰
2. Transformer

- Transformer 또한 Recognition 모델에 활용된다.
A Simple and Robust Convolutional-Attention Network for Irregular Text Recognition · Hulk의 개인 공부용 블로그
A Simple and Robust Convolutional-Attention Network for Irregular Text Recognition 15 May 2019 | ml ocr 논문 링크 읽어보니 Transformer를 가져다 쓴게 거의 전부임.. 읽은게 아까워서 간단히 정리하고 넘어가자! Overview irreg
hulk89.github.io
'DeepLearning|MachineLearning' 카테고리의 다른 글
| TTA(Test-Time Augmentation) (0) | 2022.04.28 |
|---|---|
| Deep Pose (0) | 2022.01.21 |
| Face Detection (0) | 2022.01.13 |
| Segmentation (0) | 2022.01.05 |
| Object Detection (0) | 2021.12.29 |



