Object detection
- 이미지 내에서 물체위치 및 종류를 찾아내는 것
- 이미지 기반의 문제를 풀기 위해 사용되는 기법
Ex) 차량 , 사람 detection, 사람얼굴 detection 등
용어
1. Object Localization

Localization이란 이미지 하나의 물체가 있을 때 물체의 위치를 특정
Detection이란 다수의 물체가 있을 때 각 object의 존재여부를 파악하고 위치를 특정하며 클래스 분류까지 수행
이미지 내에서 물체의 위치를 표현하는 방법에는 Bounding Box, Object Mask로 표현하는 방법이 있다.
2. Bounding Box
Bounding Box는 이미지 내에서 물체의 위치를 사각형으로 정의하고 꼭지점의 좌표로 구현
- 1. 전체 이미지의 좌측 상단을 원점으로 정의하고 바운딩 박스의 두 좌표(좌상단 좌표, 우하단 좌표)로 표현하는 방식
- 2. 바운딩박스의 width와 height로 정의 하는 방식 ==> 좌측 상단의 점에 대한 위치로 물체의 위치를 정의할 수 있다.
from PIL import Image, ImageDraw
import os
img_path=os.getenv('HOME')+'/imagedirectory/image.jpg'
img = Image.open(img_path)
draw = ImageDraw.Draw(img)
draw.rectangle((200, 30, 600, 400), outline=(0,255,0), width=2)
img
3. Intersection over Union( IoU )

바운딩 박스가 있을 때 만든 Localization 모델이 인식한 결과를 평가하려면 지표(metric)를 사용해야 하는데
면적의 절대적인 값에 영향을 받지 않도록 두 박스의 차이를 상대적으로 평가하기 위한 방법 중 하나가 IoU
교집합의 영역을 합집합의 영역으로 나눈값
빨간색 영역 $A_p$ 는 예측과 정답 $A_{gt}$(ground truth)의 교집합인 영역이고
회색 영역이 합집합인 영역일 때, IoU는 빨간영역/회색영역
Ground truth와 예측값 영역이 100% 일치한다면 IoU의 값은 1이 나온다.
Localization
1. Target Label

$P_c$ 는 물체가 있을 확률이고, $C_1$,$C_2$,$C_3$은 각각 클래스 1,2,3 에 속할 확률이고
$P_c$ == 0 이면 배경인 경우이다.
필요에 따라서 $C_1$,$C_2$,$C_3$와 $P_c$를 분리하여 다른 활성화함수를 적용하고 손실함수계산 가능
그리고 바운딩 박스를 정의하기 위한 4개의 노드가 추가된다.
$b_x$, $b_y$는 좌측 상단의 점을 표현하는 x,y 축의 좌표
$b_h$, $b_w$는 바운딩박스의 높이와 폭
Classification 모델 대신 output을 추가하여 localization 모델을 구성한다고 했을 때, 전체적인 모델을 Keras로
import tensorflow as tf
from tensorflow import keras
output_num = 1+4+3 # object_prob 1, bbox coord 4, class_prob 3
input_tensor = keras.layers.Input(shape=(224, 224, 3), name='image')
base_model = keras.applications.resnet.ResNet50(
input_tensor=input_tensor,
include_top=False,
weights='imagenet',
pooling=None,
)
x = base_model.output
preds = keras.layers.Conv2D(output_num,1,1)(x)
localize_model=keras.Model(inputs=base_model.input, outputs=preds)
localize_model.summary()
Detection 1. Sliding Window, Convolution
Multi object detection을 통해 이미지에 있는 여러 물체를 한꺼번에 찾아야 할 때
1. 슬라이딩 윈도우

전체 이미지를 적당한 크기로 나누고 각 영역에 대해 Localization network를 반복 적용해 보는 방식 == Sliding window
원본 이미지에서 잘라내는 크기를 윈도우 크기로 하여 그 영역을 이동시키면서 수행
슬라이딩 윈도우의 단점
- 많은 window영역에 대해 돌아가면서 하나식 계산해야하므로 시간이 많이 걸리고 비용이 많이 든다.
- 물체의 크기가 다양하면 여러가지 크기의 window로 돌아가며 detecting해야하므로 처리속도 문제가 심각해진다.
2. Convolution

sliding window 의 단점인 연산량과 속도를 개선하기 위한 방법 중 하나
sliding window로 localization을 수행하는 방식처럼 순차적인 연산이 아니고 병렬적으로 동시에 진행됨에 따라 속도 면에서 효율적
Detection 2. 앵커박스(Anchor box), NMS
1. 앵커 박스
- 서로 다른 형태의 물체와 겹친 경우에 대응가능
- 한 개의 그리드 셀에 대한 결과값 벡터에 물체가 있을 확률, 2개의 클래스, 바운딩 박스 4개로 총 7개의 차원
- Anchor box 1은 사람을 위해 설정한 크기이고, Anchor box 2는 차를위해 설정한 크기
- y label을 보면 output dimension이 두 배가 된다.
- 차만 있는 경우 Anchor box 1의 $P_c$가 0이 되고 차를 담당하는 Anchor box 2는 $P_c$가 1이 되도록 클래스와 바운딩 박스를 할당
- 한 그리드 셀에서 앵커 박스에 대한 물체 할당은 IoU로 가능
- 두 개의 앵커 박스가 있는 경우 IoU가 더 높은 앵커 박스에 물체를 할당
-

2. NMS(Non-Max Suppression)

Anchor box를 사용하지 않더라도 2X2 격자 셀에 모두 걸친 물체가 있는 경우 하나의 물체에 대해 4개의 Bounding box를 얻게 되는데 이 여러개의 박스를 하나로 줄여줄 수 있는 방법 중 하나
- 겹친 박스들이 있을 경우 가장 확률이 높은 박스를 기준으로 기준이 되는 IoU 이상인 것들을 없앤다.
- IoU 기준으로 없애는 이유는 어느 정도 겹치더라도 다른 물체가 있는 경우가 있을 수 있기 때문
- 이때 Non-max suppression 은 같은 class인 물체를 대상으로 적용
NMS(Non-max suppression)는 IoU를 기준으로 박스를 없애게 되는데, IoU기준이 0.3 과 0.5 중 박스가 많이 남게 되는 것은?
- IoU 기준이 일정 이상인 경우를 NMS 연산을 통해서 가장 높은 score 하나를 남기게 되는데, 문턱이 낮은것이 많은 박스를 없애게 된다.
- 그러므로 0.3인 경우 더 많은 박스가 사라지고, 0.5인 경우가 박스가 많이 남게된다.
정리
- Convolution으로 슬라이딩 윈도우를 대신함으로써 여러 window를 병렬로 object localization 수행을 하게 되어 속도 측면의 개선.
- Anchor box는 겹친 물체가 있을 때, IoU를 기준으로 서로 다른 Anchor에 할당하도록 하여 생긴 영역이 다른 물체가 겹쳤을 때도 물체를 검출할 수 있도록 할 수 있다.
- Non-max suppression은 Object detection 결과들 중 겹친 결과들을 하나로 줄이며 더 나은 결과를 얻게 한다.
Detection Architecture
Detection task의 더 나아간 방법들
딥러닝 기반의 Object Detection 모델은 크게 Single stage detector, Two stage detector 로 구분
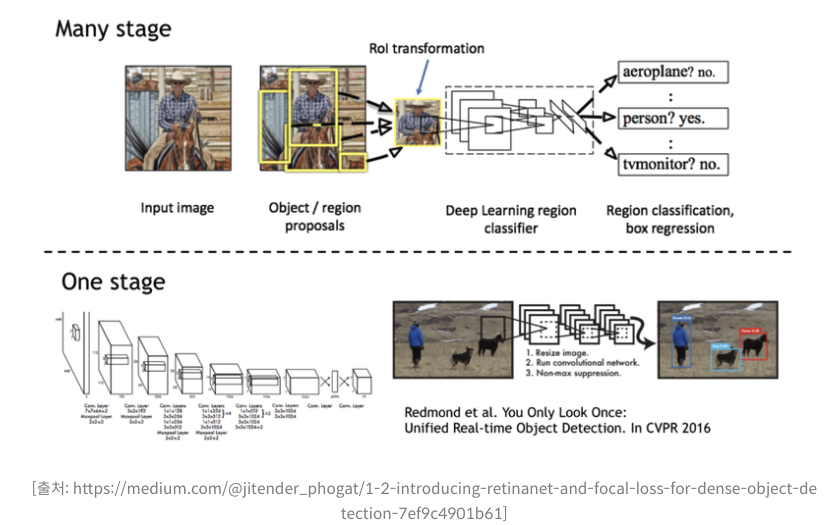
- Many stage 방법에서는 물체가 있을 만한 위치의 후보(Proposal)들을 뽑아내는 단계, 실제로 물체가 있는지를 classification/regression을 수행하는 단계. Ex) Faster-RCNN
- One stage 방법은 객체의 검출과 분류, 바운딩 박스 regression을 한번에 하는 방법. Ex) YOLO
당연히 one stage 를 통해 한번에 연산하는것이 빠르다.
Object Detection 방법은 엄청나게 많지만
Two-stage detector : Fast RCNN ==> Faster RCNN의 변천사와
One-stage detector : YOLO 및 SSD 로 알아본다.
1. Two-stage detector
RCNN
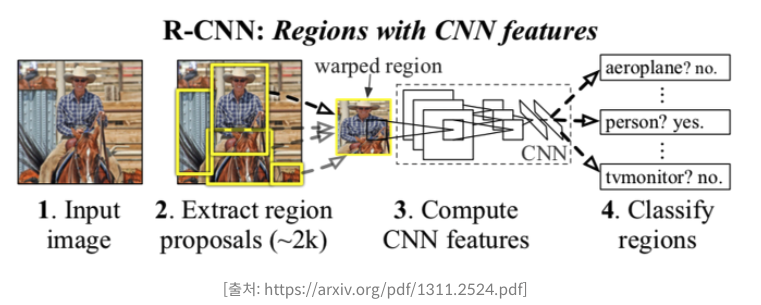
- RCNN은 물체가 있을만한 후보 영역을 뽑아내는 "Region proposal" 알고리즘과 그 후보 영역을 분류하는 CNN을 사용
- 이때 proposal 을 만들어내는 데에는 selective search라는 비 신경망 알고리즘이 사용.
- 이후 후보 영역의 Classification과 바운딩 박스의 regression을 위해 신경망을 사용
Fast RCNN

- RCNN은 한 이미지에서 특성을 반복해서 추출하므로 비효율적이고 느리다는 단점.
- RCNN의 단점을 보완한 Fast RCNN에서는 후보영역의 classification과 바운딩 박스 regression을 위한 특성을 한 번에 추출
- RCNN과의 차이는 이미지를 Sliding window 방식이 아닌, CNN을 거친 Feature Map(특성맵)에 투영하여 Feature Map을 잘라낸다.
- 잘라낸 특성 맵의 영역은 여러가지 모양과 크기를 가지므로 해당 영역이 어떤 클래스인지 분류하기 위해 사용하는 fully-connected layer에 batch 입력값을 사용하려면 영역의 모양과 크기를 맞추어 줘야 하는 문제가 생기는데, RoI pooling이라는 방법을 제안하여 후보영역에 해당하는 특성을 원하는 크기가 되도록 pooling하여 사용

Faster RCNN
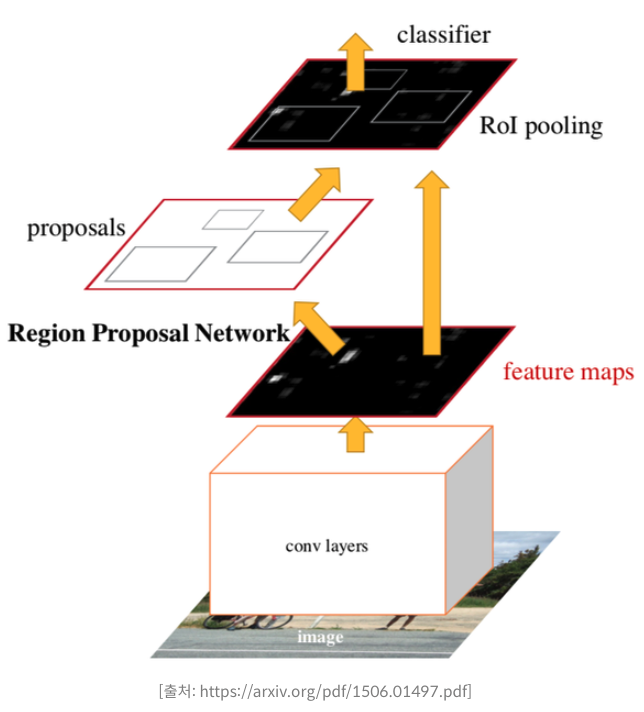
- Fast RCNN은 CNN연산을 줄였지만, region proposal 알고리즘이 병목이 된다.
- Faster RCNN에서는 region proposal 과정에서 RPN(Region Proposal Network) 신경망 사용
- 이미지에 CNN을 적용하여 특성을 뽑아내면, 특성 맵만을 보고 물체가 있는지 알아낼 수 있다.
- 이 특성 맵을 보고 후보 영역을 얻어내는 네트워크가 RPN
2. One-Stage Detector
YOLO

- 이미지를 그리드로 나누고, sliding window 기법을 convolution 연산으로 대체하여 fully-connected network 연산을 통하여 그리드 셀 별로 바운딩 박스를 얻어낸 후 바운딩 박스들에 대해 NMS 한 방식
- 두 가지 클래스가 한 셀에 나타나는 경우 정확하지는 않지만 매우 빠르다.
SSD(Single-Shot Multibox Detector)

CNN에서 뽑은 특성 맵의 한 칸은 큰 영역의 정보를 담게 된다. 여러 convolution layer와 pooling을 거치기 때문에 특성 맵의 한 칸은 처음 입력 이미지의 넓은 영역을 볼 수 있다.
- YOLO의 경우 이 특성이 담고 있는 정보가 동일한 크기의 넓은 영역을 커버하기 때문에 작은 물체를 인식하기에 적합하지 않다.
- SSD는 다양한 크기의 특성 맵으로부터 classification과 bounding box regression을 수행한다.
'DeepLearning|MachineLearning' 카테고리의 다른 글
| TTA(Test-Time Augmentation) (0) | 2022.04.28 |
|---|---|
| Deep Pose (0) | 2022.01.21 |
| Face Detection (0) | 2022.01.13 |
| OCR(Optical Character Recognition) (0) | 2022.01.06 |
| Segmentation (0) | 2022.01.05 |



