computer vision 분야에서 가장 중요한 것은 이미지분류.
컴퓨터는 이미지를 볼 때, RGB값을 나타내는 수많은 숫자들의 나열로 본다.


또한 사진마다 각도, 빛, 고양이자세, 숨어있는 등 여러 변수에 숫자들은 모두 달라질것이며, 인식하기가 힘들어진다.
그래서 데이터에 기반한 접근법을 생각하게 되었다.
많은 사진들로 그 사진들이 무엇인지 먼저 정답을 알려주고 그렇게 학습된 모델로 사진을 분류를 하면 잘되지 않을까라는 생각으로.
사람도 처음 태어났을 때 자신도 모르게 수많은 경험과 사진등을 보면서 저것이 무엇인지 알게되는 것처럼
컴퓨터 또한 갓 태어난 아이라고 생각하고 가르쳐준다는 느낌으로 생각을하면 이해가 조금 더 쉽게 된다.
그리하여 처음 고안해낸 분류방법은 NN(Nearest Neighbor) == '가장 가까운 이웃' 방법.

이때 사용할 데이터셋은 CIFAR-10 데이터셋을 사용.
데이터셋마다 특징이 다 다르지만, CIFAR-10 데이터셋은 총 10가지의 카테고리를 50,000장의 train images와 label, 10,000장의 test images로 모아놓은 데이터셋이다.
이 사진들을 컴퓨터에 Nearest Neighbor 방식으로 가르치는 방식.

L1 distance 방식을 통해 사진이 비슷한지 알 수 있다.
원리는 컴퓨터에서는 이미지를 숫자들의 집합으로 보는데, 그 숫자들의 크기가 비슷하다고 하면 이미지도 비슷하다는 원리.
이 원리로 test image에서 train image의 숫자들을 빼고 절대값을 씌워주면 각 숫자간의 거리가 나오고, 이 숫자간의 거리가 사진사이의 다른 정도를 나타내는 지표로 생각을 한다. 결과값을 모두 더하여 하나의 숫자로 나타내고 그 하나의 숫자로 판단.
즉, 두 이미지의 숫자를 빼서 그 크기가 작게나오면 비슷한 이미지일것이고, 숫자가 크다면 다른 이미지일 확률이 높다는 느낌
Train
- 이미지를 기억하는 부분

Predict
- 입력 데이터를 train_data와 비교하여 어떤 Label값을 가질 지 예측
- 여기서는 Nearest Neighbor를 사용하므로 기억한 이미지를 빼준다.

이 방법은 predict과정이 시간이 매우 오래걸리므로 문제가 있다.

Nearest Neighbor 알고리즘으로 예측한 그림.
가운데에 노란색으로 칠해진 부분이 초록색이 되어야 할 것 같은데 노란색으로 되어있다.
이 문제를 해결하기 위해 고안된 방법이 K-NN
K-NN의 원리는 주변 K개의 점을 보았을 때 가장 비슷한 것이 정답일거라는 원리.
K-Nearest Neighbor algorithm에 영향을 미치는 parameter에는 크게
- K값
- Distance Metric(L1, L2 distance)
1. K 값을 조절함으로써 경계선을 부드럽게, 혹은 영역 분류를 더 잘하게 된다.

K- Nearest Neighbor로 훈련시킨 결과

2. Distance metric에 따라서는 경계선의 차이를 볼 수 있다. 보통 L1, L2 distance를 사용

L1, L2를 어디에 어떻게 사용할지에 대해서는 보통
특정 vector가 개별적인 의미를 가지고 있으면 L1 distance(예 : 사원의 근무년수, 봉급 등)
의미를 모르거나 의미가 별로 없을 때는 L2 distance.

K=1이라고 하고 L1, L2 distance의 결과 차이를 확인하면 위와 같다.
여기서 K값, distance metric등의 파라미터들을 Hyper-Parameter라고 정의
그런데, 어떻게 하면 Hyper-Parameter의 설정을 잘 할 수 있을까?

기계학습의 궁극적인 목적은 한번도 보지 못한 데이터에서 잘 작동해야하는게 목적이다.
Dataset이 잇을 때 train, validation(검증), test로 나누어 한번도 보지못한 데이터의 분류를 잘 하는 Hyper-parameter를 선정.

더 나아가 교차검증(Cross-Validation)을 하면 조금 더 성능을 높여주는 Hyper-parameter값을 찾을 수 있다.
하지만 딥러닝 같이 큰 모델을 학습 시킬 때에는 계산량이 많아 잘 사용하지는 않는다.
Linear Classification
linear classification은 Neural Network를 구성하는 가장 기본적인 요소이며, Parametric model의 가장 단순한 형태.
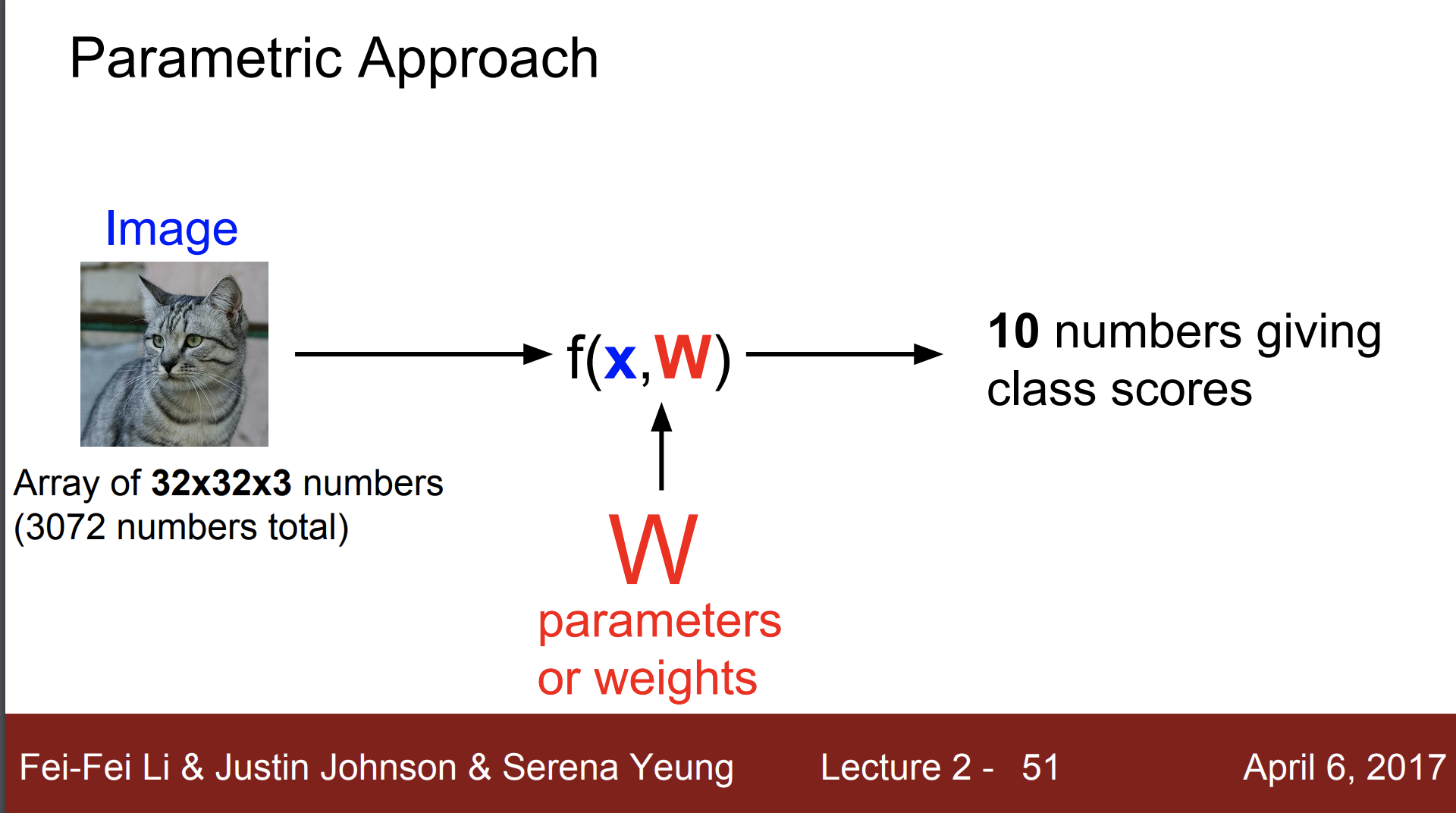
입력 이미지가 32X32X3 이고 10개의 클래스 중 하나를 분류하는 문제가 있다고 하면
W에 train data의 정보가 들어있어 test 시간을 단축
딥러닝은 함수 f(x,W) 의 구조를 잘 설계하는 일이며, 가중치 W와 데이터 X를 조합하는 가장 쉬운 방법은 곱하는것인데, 이것이 Linear Classification

입력이미지 32X32X3 을 길게 펴서 열 vector로 만들면 3,072 차원의 vector가 된다.
이 3,072 차원의 vector가 10개의 클래스 score가 되어야한다 ==> 10개의 클래스에 해당하는 각 score를 의미하는 10개의 숫자를 얻는 것.
고로 W는 10 X 3,072 의 행렬
b는 bias로 10차원의 열 vector. 데이터와 무관하게 특정 클래스의 우선권을 부여한다. 주로 dataset이 불균형할때 사용.
(bias값을 이용하여 linear에 더 잘 맞게 하도록 하는 방법)
Linear classifier로 어려운 문제들이 있는데

한 클래스가 다양한 공간에 분포하는 비선형적인 문제에서는 linear classifier로 분류하기 어렵다.