공부를 하며, 내가 이해한 방향으로 끄적이는 글이므로 이 글이 무조건적인 정답은 아니다.
Classification task의 논문들의 코드들을 보면, 보통 성능을 평가하기 위해 Accuracy(정확도), Recall(재현도), Precision(정밀도), F1_score등이 쓰이는데, 그냥 남들이 쓰니까 나도 써야지 하며 쓰는것보다는 왜, 어떻게, 무슨 원리로, 분류모델에 쓰는지를 제대로 알면 그에 대한 성능을 끌어올리는데에 있어서 도움이 될까 공부를 하며 글을 쓴다.
먼저, 위의 네가지의 평가지표를 이해하려면 오차행렬을 알아야한다.
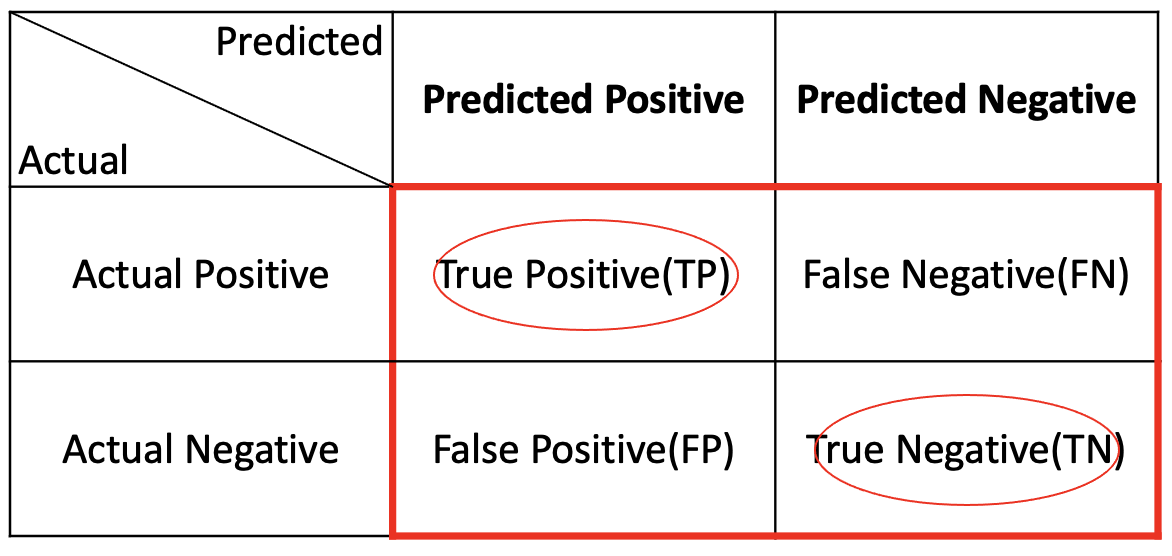
1. 오차행렬(Confusion Matrix)
정의 : 예측성능을 측정하기 위하여 예측값과 실제값을 비교하기 위한 표

TP, TN : 실제값(Actual Positive, Actual Negative)을 맞게 예측
FP, FN : 실제값과 다르게 예측
즉, 위의 문제들이 수능문제라고 치면
TP는 수능문제에서 ~~의 문제에서 맞는것을 고르시오. ==> 정답맞춤
TN은 수능문제에서 ~~의 문제에서 틀린것을 고르시오. ==> 정답맞춤
FP는 수능문제에서 ~~의 문제에서 틀린것을 고르시오. ==> 정답틀림
FN은 수능문제에서 ~~의 문제에서 맞는것을 고르시오. ==> 정답틀림
위와 같이 이해를 하였다.
2. Accuracy(정확도)
전체 데이터 중 모델이 올바르게 분류한 비율.
즉, 정확도는 틀린부분은 빼고, 맞춘부분에만 초점을 맞춰 전체데이터로 나눈 값.

3. Recall(재현도)
Actual value(실제값)에서 positive인 데이터 중 모델이 positive라고 분류한 비율.
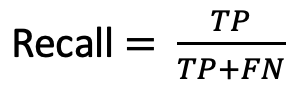

4. Precision(정밀도)
Predicted value(예측값)에서 positive라고 분류한 데이터 중 실제값이 positive인 비율


5. F1 Score
Precision, Recall 의 조화평균
조화 평균이란?
1. Precision(P), Recall(R)이라는 두 수가 있을때, P와 R의 역수 즉, 1/P, 1/R의 평균을 구하고
2. 그럼 (1/P + 1/R) / 2 가 되는데, 이 값을 다시 역수로 취한다.
3. 식의 순서는 아래와 같다.



분류모델의 성능을 평가할 때 사용되며, 0 ~ 1 사이의 값을 가지고 값이 높을수록 성능이 좋다고 평가된다.
불균형한 데이터셋에서 모델을 평가할때 특히 유용.
만약 단순한 평가식을 사용한다면, 매우높은값 하나가 낮은값들을 상쇄시킬 수 있어서 때에 따라서 정확한 결과를 얻을 수 없지만, F1-score를 사용하여 평가를 한다면 Precision값과 Recall값 모두 높은값이 나와야 전체 평균도 높게 나오므로 더 정확한 결과를 얻을 수 있다.
F1-Score의 이해를 돕기위한 예시
Accuracy의 한계
- 전체 샘플 중 올바르게 예측된 샘플의 비율을 나타내므로, 데이터셋이 불균형하다면 성능에 신뢰가 떨어질 수 있다.
- 예를들어 A,B,C,D,E 총 5개의 클래스로 이루어진 데이터셋이 있다고 가정하고 각각 A B C D E = (500, 100, 50, 30, 20) 개의 불균형한 데이터셋이라고 가정한다.
- Model_1 : A,B,C,D,E 클래스에 대해 적당히 예측을 하는 모델
- Model_2 : A클래스에만 예측을 잘 하는 모델
- 이때, Model_2가 A 클래스에 대해서만 잘 예측한다고 하면 Accuracy는 매우 높게 나올것이다. (맞춘개수 / 전체 샘플 수 이므로)
- 따라서 Accuracy만으로는 모델의 성능을 평가하기는 어렵다고 볼 수 있다.
아래는 Model_1 과 Model_2의 Accuracy와 F1-score를 같이 비교한 표이다.
Model_1

Model_1의 Accuracy : (300+60+25+15+10) / (500+100+50+30+20) ≈ 0.55
Model_1의 평균 F1_Score : (0.6+0.6+0.5+0.5+0.5) / 5 = 0.54
Model_2

Model_2의 Accuracy : (495+20+0+0+0)/(500+100+50+30+20) ≈ 0.69
Model_2의 평균 F1_Score : (0.99+0.20+0.00+0.00+0.00) / 5 = 0.24
Accuracy 성능만 보았을 때에는 Model_2 > Model_1 이지만
F1_Score 성능을 보면 Model_1 > Model_2 인걸 볼 수 있다.
위의 예시는 Accuracy만으로는 불균형한 데이터셋을 반영하지못하고, 모델의 성능을 과대평가할 수 있음을 보여준다.
'DeepLearning|MachineLearning' 카테고리의 다른 글
| DeepLearning 기초 개념 : batch_size, steps, epoch, iteration (0) | 2022.04.28 |
|---|---|
| TTA(Test-Time Augmentation) (0) | 2022.04.28 |
| Deep Pose (0) | 2022.01.21 |
| Face Detection (0) | 2022.01.13 |
| OCR(Optical Character Recognition) (0) | 2022.01.06 |



